
The Dependency Graph
...is not the call graph!

We’re midway through my detour from the “testing around effects” series. In the previous post, we learned about the difference between static and dynamic function calls. In this post, I want to explore a closely related topic: the difference between implementation dependencies and interface dependencies. We’ll see how each of these types of dependencies affects the structure of the dependency graph.
Things I want you to take away from this post:
The dependency relationships in our software form a graph. The dependency graph often mirrors the call graph, but they are not the same thing.
Dynamic calls cause the dependency graph to diverge from the call graph.
Codebases with deep dependency graphs spawn mysterious bugs. By contrast, debugging is easier in systems where the dependency graph is shallow.
Dynamic calls can help us create shallow dependency graphs, even when the call graph must be deep.
A Definition of Dependency
First things first, let’s clarify what I mean when I say “dependency”. It might seem like an elementary term, but I’m going to be using it in a specific way in this post, and I want to make sure I cover all my bases. So:
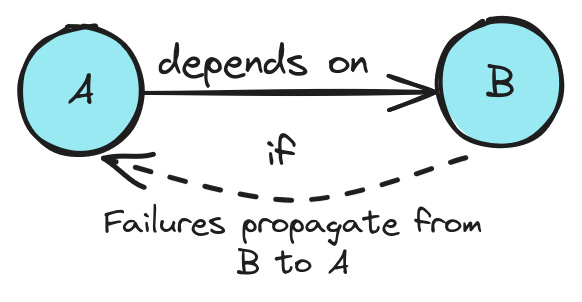
Thing A depends on thing B if changes to or failures in B might cause failures in A. This definition might seem vague or hand-wavy, but it is as specific and formal as I care to get at the moment. Dependency is one of those things that looks more complicated the longer you stare at it, so I prefer to lean back and squint. We’ll see some of those complications shortly.
The Dependency Graph
It’s straightforward to draw a graph of dependencies in a codebase:
The nodes of the graph are the things (units of code or concepts) that can be depended on.
The arcs of the graph are dependency relationships. We draw an arrow from A to B if A depends on B.
Note the direction of the arrows. Some people like to draw dependency graphs with the arrows going the other way. I’m not going to say that’s wrong—it’s an arbitrary choice, after all—but I will point out that my way of doing it is consistent with UML conventions, and is therefore more likely to be widely understood.
Two Types of Dependency
The most straightforward type of dependency occurs when one function statically calls another. If function A statically calls function B, then A depends on B, because any bugs in B might cause bugs in A. I’ll call this type of dependency an implementation dependency1. When all the dependencies in a codebase are implementation dependencies, the dependency graph will look identical to the call graph.
Things get a bit more interesting in the presence of dynamic calls. Each dynamic call is an opportunity for an implementation dependency to be replaced by an interface dependency. Interface dependencies form whenever a few conditions are met:
Our code makes a dynamic call to some other function.
We don’t know or care what specific function is on the other side of that dynamic call…
…but we need that function to adhere to certain guidelines, or have certain properties. At a minimum, we probably need it to accept the types of arguments we’re passing to it, and return the right type of value. The function may also need to have other properties, like referential transparency, idempotence, commutativity, etc. in order for the algorithm we’re using to guarantee correct results.
Under these conditions, the properties we require of the function we’re calling constitute an interface. Our code depends on that interface. We can imagine an interface as something like a contract that defines the interaction between two parties, an implementer and a client2. The code that calls the interface is the client, and the code that receives the call is the implementer.

Now let’s think about which way the dependency arrows go in this situation. If the interface changes—that is, if the terms of the contract change—its clients might not be able to function. Thus, clients depend on the interface.
Implementers also depend on the interface, because if the terms of the contract change, then the implementers might not be able to fulfill the contract anymore—and fulfilling the contract is part of their job.
So, the dependency graph for an interface dependency looks like this:

In other words, the client and implementer are peers in the dependency graph. Neither one can be broken by changes to the other.
What’s the point?
As should be clear from the length of my description above, interface dependencies introduce more (apparent) complexity than implementation dependencies. So why should we ever prefer them?
The answer has to do with the dependency graph I drew above. I drew the interface node with a dotted border to indicate that it isn’t made out of procedural code. Indeed, in a dynamically-typed language, the interface might exist only in our heads. Since the interface contains no code, it can’t have any dependencies, which means nothing else in the system can break it. If a chunk of code depends only on interfaces, that means that nothing can break that code, either. Interfaces thus allow us to provide ironclad stability guarantees. Imagine if you could ship code changes with absolute confidence that certain parts of your system would not break! Interface dependencies can give you that confidence.
An Analogy
To illustrate why interface dependencies are so useful, consider a physical interface that exists all around us: the humble electrical outlet.

There are dozens of electrical outlets in my house. Some are connected to switches, some are part of power strips with surge protectors, some have ground fault circuit interrupters, and some have none of these features. But all of them implement a simple contract: they provide 120 volts of 60 Hz AC to a standard US plug. Because all of my electrical outlets implement a common interface, I can plug any appliance into any outlet and be confident that nothing will explode. And if the utility company upgrades the power lines, or replaces gas-fired power plants with solar, I don’t need to buy new appliances, as long as I’m still getting 120 volts.
There are subtler benefits, as well. The ubiquity of electrical outlets, and the appliances that plug into them, means that I can use different combinations of outlets and appliances to diagnose failures.

Suppose I’m trying to make coffee one morning and discover that my electric kettle doesn’t work. Is the problem with the kettle or the power outlet? I can test the kettle by plugging it into a different outlet, and I can test the outlet by plugging in a different appliance. These tests let me quickly determine if I need to call an electrician or a kettle repair person3.
The same flexibility that lets me diagnose failures makes it easy to work around those failures. If one outlet stops working, I can just use another one, since there’s nothing wrong with the kettle. In the context of interface dependencies, if one part of the system breaks, the other parts are unaffected.
Imagine an alternate reality where, instead of an electric kettle, I had a water-heating device built into my kitchen counter. (This is equivalent to a kettle with an implementation dependency on a particular outlet). It might look slick, but if the power supply stops working one day, I’m stuck. Since I can’t isolate the broken part, I can’t work around the problem or even diagnose it. In the context of implementation dependencies, any component that uses a broken component is as good as broken.
The Dependency Graph Is Not the Call Graph
Enough philosophizing and analogizing. It’s high time for a code example.
Here’s a simple (if contrived) example to show how the dependency graph changes in the presence of interface dependencies. We’ll start with a function printMuppetNames, which logs the names of some characters from The Muppet Show:
const muppets = [
{name: "Kermit"},
{name: "Miss Piggy"},
{name: "Gonzo"},
];
function printMuppetNames() {
console.log(names(muppets));
}
function names(muppets) {
const results = [];
for (const muppet of muppets) {
results.push(name(muppet));
}
return results;
}
function name(muppet) {
return muppet.name;
}printMuppetNames calls names, which calls name. All of these calls are static. Therefore, the dependency graph and the call graph both look like this:

Now, let’s consider an alternative implementation of the same behavior, using Array.map instead of a for loop:
const muppets = [
{name: "Kermit"},
{name: "Miss Piggy"},
{name: "Gonzo"},
];
function printMuppetNames() {
console.log(muppets.map(name));
}
function name(muppet) {
return muppet.name;
}In this implementation, the call graph still has the same linear shape as before: printMuppetNames calls map, and map calls name. However, the dependency graph has changed. printMuppetNames now has two direct dependencies, on map and name, and map doesn’t depend on anything in our code.

Even though map is calling name, it doesn’t depend on name. Recall that our definition of dependency says that A depends on B if a bug in B can cause a bug in A. If name has a bug, that doesn’t create a bug in map. map might be used in thousands of places in our codebase, and we can confidently say that none of those usages are jeopardized by a problem with name.
How is this wizardry possible? The secret is that map and name both depend on an interface: one so tiny and elementary that if you blink, you’ll miss it. That interface is simply the concept of a function.

That is, map needs to be provided with a function in order to do its job, and name fits the bill. The only constraint is that the function passed to map needs to accept an element of the mapped array as its argument. name satisfies this constraint because it accepts a muppet, and our array contains muppets. There’s a way to formalize this constraint with TypeScript types, which allows the compiler to prove that everything’s copacetic, but we’ll leave that for a future post.
(If you’d like to be notified when I write about types, or anything else, why not hit the subscribe button?)
Why any of this matters
Bugs and breaking changes are contaminants that propagate backward through the dependency graph. E.g. say I’m the author of a library, and I release a new version that has a bug. That bug will affect both the systems that use my library directly, and everything that depends on those systems. Ouch.
Bugs are harder to diagnose when the symptom appears many steps away from the cause. If a dependency of a dependency of a dependency changes and causes a failure in my code, I’m going to have to do a lot of digging to find the source of the problem. When the dependency graph is shallow, on the other hand, bugs can’t propagate as far, and debugging is easier. This implies that deep dependency graphs can be problematic.
If we are used to using static calls for everything, the motivation to avoid deep dependency graphs puts us in a bit of a quandary. That’s because “divide and conquer” has traditionally been the overarching strategy when it comes to software design—it’s the approach I was taught in school, anyway. With divide and conquer, we solve big problems by recursively breaking them down into subproblems, until the problems are so tiny that we can solve them with a single gesture. Unfortunately, this strategy tends to produce deep call graphs, and when all calls are static, the dependency graph will also be deep. The difficulty of debugging a deep dependency graph makes it hard to continue growing a large4 software system designed via a top-down, divide-and-conquer approach.5
The solution is to “cut” the dependency graph—to introduce dynamic calls at appropriate abstraction boundaries. By doing this, we can keep the dependency graph shallow, and enable even our largest software systems to continue growing sustainably.
Tradeoffs
There is a tradeoff to using interface dependencies, of course. As I noted earlier, when two components interact via an interface, they are peers in the dependency graph. That peer relationship gives you a lot of flexibility to plug different parts together, but the cost is that something or someone has to do the plugging. Generally, that’s you, the programmer responsible for the system.
Going back to the electrical analogy—I happen to like my electric kettle + wall outlet setup, but the downside (compared to the hypothetical built-in countertop water heater) is that I need to know about two things, the kettle and the outlet, and I need to manage their interaction. That is, I have to be more involved in the system, and understand more about how it’s put together. Someday, I will write a philosophical ramble about being involved, and the value and costs thereof, but for now I will spare you the digression. In the meantime, you can visit your local library and check out Zen and the Art of Motorcycle Maintenance, which treats the issue in some depth.
Wrap-up
We covered a lot of ground in this post, and I’m sure I glossed over some details. As always, feel free to ask questions in the comments section below. I really value your feedback.
If I’m reading the tea leaves right, the next post will return to the “testing around effects” series. We now have all the pieces in place to talk about dependency injection and dependency inversion, two alternative views of the “generalization” strategy for making code testable. Stay tuned.
The terms “implementation dependency” and “interface dependency” are used in https://www.researchgate.net/publication/2565865_On_the_Notion_of_Variability_in_Software_Product_Lines
Indeed, the term “contract” has been used in the sense in which I’m using “interface” here. Maybe I should have said “contract” instead of “interface”, but I wanted to be consistent with “interface dependency”. Time will tell if this was a mistake.
The kettle story is a true story, and, as usual, truth is more interesting than fiction. It turned out that both the kettle and the outlet were okay. The outlet’s circuit breaker had just tripped. It was a weird GFCI outlet that didn’t have built-in test/reset switches—those were located on another outlet on the other side of the room!
“Large” is relative, but as a rule of thumb, by the time I have 5 or 6 levels of static calls, I am feeling the pain.
Compare what I wrote in my post on The Call Graph: “Once [the program] grows beyond a certain size, you can’t keep it all in your head at once, and navigating it starts to feel bewildering. […] Every few months or so, I feel the need to draw out a call graph for a section of code on paper. When I do, I take it as a strong signal that the code is a mess.”
Nice post, Ben!
One question: do you think that an interface also has a dependency on the implementer? Say I’m a baker and I posted in my menu 2 buns for a buck. I run out of eggs so no buns. In that sense, doesn’t that error affect the contract I provided? Or would you argue that error is actually propagated to the customer?